


The popularity of machine learning is perhaps surpassed only by the level of confusion surrounding what it actually is, and how it can be applied to the problem that you have. This post intends to deconstruct the machine learning process and, with some luck, help you to understand how to formulate a problem as a machine learning one, by breaking it down into abstract components. Additionally, it will hopefully enable you to more easily see opportunities to apply machine learning techniques to the problems that are relevant to you. With this in mind, we can start with a very basic definition: In a fundamental sense, machine learning is the process of iteratively constructing a dynamic set of parameters or ‘state’; that can be used to map input observations to some form of output.

If this output is known prior to training and used to provide information by calculating some form of residual or ‘loss’ it is considered to be ‘supervised’, otherwise, some additional metric or score may be calculated, and minimised or maximised in an ‘unsupervised’ manner. In the case of supervised learning there are two main families of machine learning models: Regression models reproduce one or more continuous values; and Classification models learn to differentiate inputs into their respective classes; think of this like a categorical variable that describes each observation. In the case of Unsupervised learning, there is typically one key approach, often termed Association (or clustering) models look to group observations based on a level of similarity (or dissimilarity).
Using such a basic definition, even classical statistical algorithms with optimised (or ‘learned’) parameters can, perhaps rightly be classified as machine learning, where these parameters act as the dynamic state where the learned relationship is encoded. This trend extends through more traditional machine learning algorithms (where this state is the constructed decision-tree), all the way to deep neural nets, where the state in the weighted connections between the nodes of the network. With a sufficiently large model, the number of these parameters can reach the millions, which is how machine learning algorithms are able to accurately model relationships with sufficient complexity to out-perform traditional statistical approaches.


The popularity of these approaches has however been accelerated by the exponential development in the capabilities of computational hardware, by leveraging computational power to perform more iterations across larger sets of learned parameters; leading to larger and more complex states which can encode more complex relationships between the input and output.
Whilst it is one thing to understand how machine learning algorithms work at a fundamental level, it is another thing entirely to understand how to leverage them effectively. As you are no doubt aware, the field is immense and covers areas far greater in scope than simply how to design the most effective algorithms. In a more comprehensive sense, a machine learning ‘model’ can be considered to also include the structure and transformations applied to the input observations; as the effectiveness of any algorithm is entirely dependent on the information (and the accessibility of this information) contained within the input observations.
Application in Wind Energy Analytics
With this cleared up, we can focus on how this relates specifically to challenges faced by the wind industry. Turbines and monitoring systems have continued to grow more sophisticated in terms of the data they collect and yet the key issue with many of these systems (and indeed, a key challenge with realising value from machine learning across most industries) remains the knowledge of how best to process and analyse this data to realise some kind of value. As such, many of the approaches useful to the wind industry fall into the supervised category of learning.
It is also beneficial at this point, to clarify the difference between an algorithm, which is the term used to refer to the method of computation which will be used; and the model, which refers to the larger collection of the algorithm, the relevant pre-processing steps, and the dataset itself. This distinction is important, as identical algorithms will perform very differently when applied on different dataset which have been processed in different ways. This fact highlights perhaps one of the most important takeaways from this post: The constructed dataset and the quality of the data in it is the most important factor determining the success of the model!
Within wind energy analysis, the problems posed often involve reconstructing some kind of information that is missing, cannot be trusted, or was not recorded at all; or constructing some additional information that can tell you something novel about the real-world. This is perhaps best demonstrated through two examples.
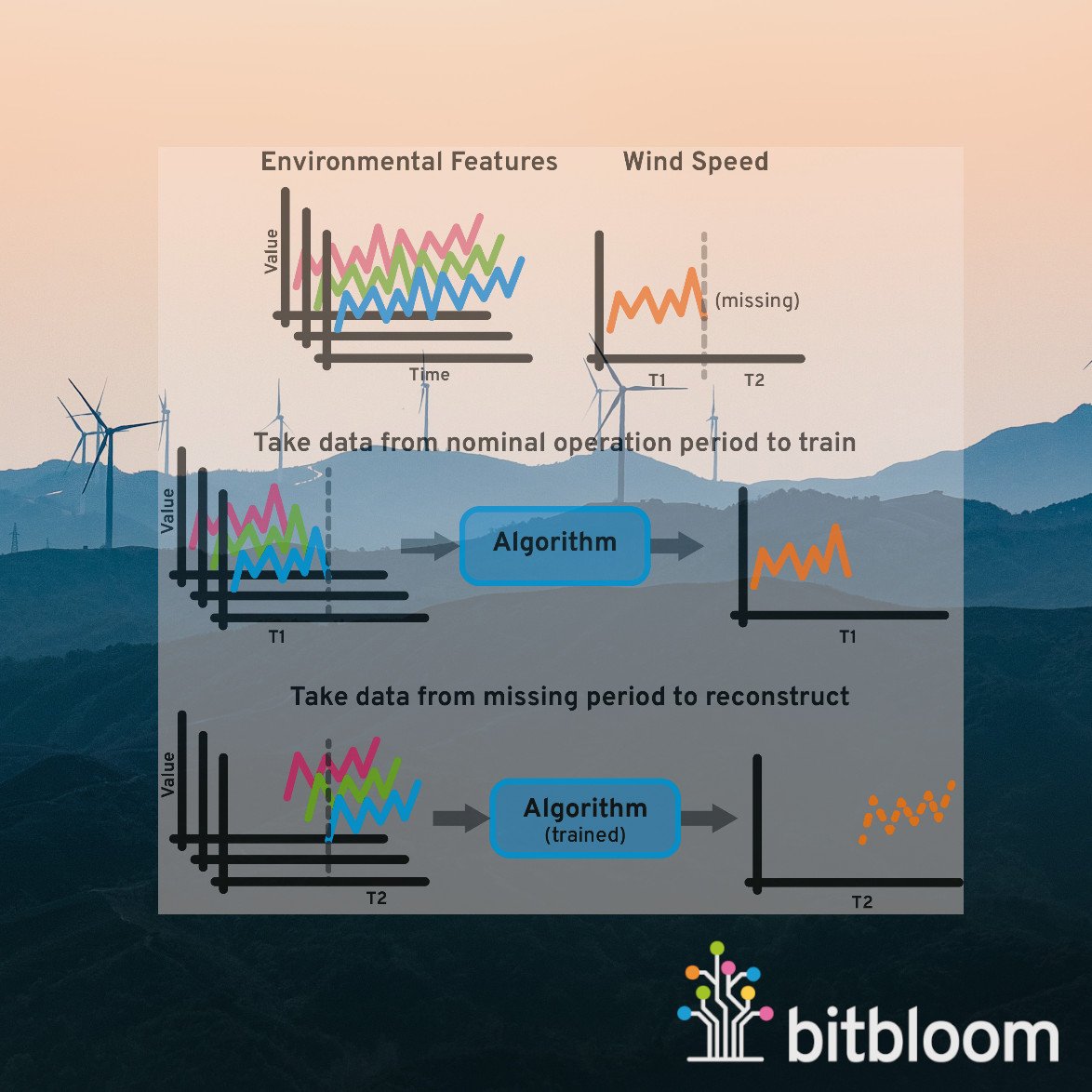
Available Power
Firstly, we consider the case where due to some unexpected downtime a turbine is not producing power for a period of time. It is useful for us to know the lost power potential for these periods, and machine learning can provide a potential solution.
By leveraging historical information, an algorithm can be trained to reconstruct a turbines’ power signal from environmental data. This data can be additional signals collected from the same turbine, or potentially external data from weather satellites. This collection of variables describes the state at the turbine, and under the assumption that a similar future state will result in a similar power production, a machine learning algorithm can be trained to learn the relationship between this environmental state and the produced power.

Once a period of downtime is encountered, this trained model can then be shown the collected environmental data for the period where the turbine was not producing power. Using the learned relationship (recall, the internal state of the model, or set of optimized parameters), the model will act as a surrogate, and be able to provide an estimate of the power that would have been produced, given the environmental state at the turbine.
Temperature Monitoring
Secondly, we consider the case where we are monitoring the temperature of a component in order to detect changes that may indicate early signs of a failure. Temperature values will vary significantly as a result of different environmental and operating conditions, making analysis of these signals to determine ‘out-of-the-ordinary’ operation more difficult than usual.
There are two options here, and they depend on what data we have access to. If the only available data we have describes normal operation of the component in question, we can use a machine learning model as a surrogate in a similar fashion to the previous example, and use the historical data to reproduce an estimate of the signal. This can be compared to the measured signal, with the residual of these two signals indicating a deviation from the expected measurement.
Alternatively, if we have data leading up to previous component failures alongside our normal operation data, we could approach this problem from a classification perspective, where we train a model to predict the likelihood that a given data period belongs to either of the two classes of operation: nominal or failing. This second approach is more direct and requires no interpretation of the results (after development, of course), however, the obvious caveat if that often, clean cut examples of the classes you are trying to identify are not readily available.

And many more…
Obviously, these cases present a small sample of the capability and potential application of ML within the domain. Notable omissions include classifying turbine operational modes, and forecasting/predictive analytics. These are topics in their own right and deserve their own respective blog posts (stay tuned for parts 2 and 3…?). Additionally, there is no mention of the required data pre-processing and potential feature engineering that may be required to construct a dataset of high enough quality for the learning process to be effective. This fact represents the greatest challenge in realising the value that Machine Learning can provide, and that is having enough expertise in managing the available data so as to construct a dataset well-suited to the problem you are attempting to solve.
Snake Oil Disclaimer
The promise of Machine Learning is large and ambitious, and whilst demonstrated to be capable of amazing things, it is necessary to understand its key limitations, and there are significant limitations. Machine learning is not a cure-all solution. Back in the introduction, it was mentioned that any machine learning algorithm will perform in direct proportion to the quality of the available dataset. This can often pose a challenge in terms of access to data of sufficient fidelity or volume.
The other obvious caveat is that there is no promise, even with a perfect dataset, that a machine learning solution will outperform a more established statistical or physics-based approach. In many cases, the relationship trying to be captured by the model may simply be too complex, or it may not be possible to collect the required data in the first place; the available measurements may fail to capture and explain this relationship, or the data describing the necessary conditions may not exist at all. Additionally, the models will often come with substantial overhead, in terms of development and raw computation. In cases where the models provide a negligible improvement, they may not actually provide any net value.
Despite these limitations, machine learning has the reputation that it does because it can work, and when it does work it has the potential to revolutionise entire industries. It will however serve anyone wishing to dive into this field well to understand that all progress is incremental, and progress in the successful application of machine learning is perhaps the most incremental of all.
Conclusions
Ultimately, Machine Learning is simple. Using Machine Learning effectively is still hard however, and the success and failure is often unpredictable and heavily dependent on the particular problem and how you have constructed (or been able to construct) your inputs and outputs. It is very much not a ‘cure for all that ails ya!’, nor even a tremendously exact science, despite what popular opinion may lead one to believe. To reiterate one final time, my best advice is to break down the problem into the information you want your model to provide, and the relevant information you have available to provide it with; and focus on the quality of this data.